 Server
Colocation
Server
Colocation
 CDN
Network
CDN
Network
 Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
 Kubernetes
Kubernetes
 API Gateway
API Gateway
As artificial intelligence continues to reshape industries, organizations are facing unprecedented demands for computing power. Training large language models, running real-time AI inference, and processing massive scientific datasets require infrastructure that goes far beyond traditional servers.
The NVIDIA H100 Tensor Core GPU Cloud server was created precisely for this new era.
Built on NVIDIA’s cutting-edge Hopper architecture, the H100 is a data center–grade accelerator engineered for large-scale AI, machine learning, and high-performance computing (HPC) workloads. With advanced Tensor Cores, massive memory bandwidth, and support for FP8 precision, it enables businesses to build and deploy next-generation AI systems faster and more efficiently.
Through Cyfuture Cloud, enterprises gain flexible, secure, and cost-effective access to NVIDIA H100 GPU—without the burden of hardware ownership.
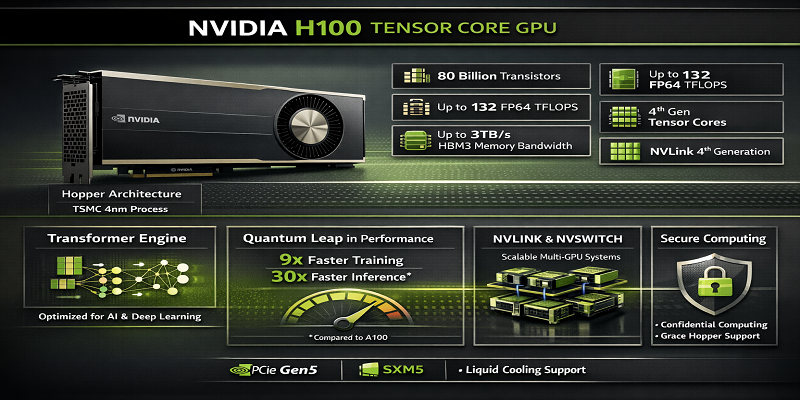
The NVIDIA H100 is NVIDIA’s flagship AI accelerator, designed specifically for modern workloads such as:
Large Language Models (LLMs)
Computer vision systems
Scientific simulations
Data analytics pipelines
Unlike consumer graphics cards, the H100 is optimized for continuous, high-density computation in data center environments. It focuses on throughput, reliability, scalability, and energy efficiency rather than gaming performance.
With up to 80GB of ultra-fast HBM3 memory and industry-leading compute capabilities, the H100 allows organizations to train and deploy models that were previously impractical on conventional hardware.
In real-world AI environments, performance is often limited not by raw compute power, but by memory bandwidth, latency, and scalability. The H100 addresses these challenges directly.
Key advantages include:
Faster model training cycles
Reduced inference latency
Higher utilization of infrastructure
Lower operational complexity
Better ROI on AI investments
For companies developing AI-driven products, these benefits translate into shorter time-to-market and stronger competitive advantage.

Up to 80GB HBM2e/HBM3
Up to 3.35 TB/s bandwidth
Enables smooth handling of large datasets and models
Supports FP64, FP32, TF32, FP16, BF16, FP8, INT8
Optimized for deep learning and transformer workloads
Improves performance without sacrificing accuracy
Up to 3,958 TFLOPS (FP8)
High FP32 and FP64 throughput for scientific computing
Designed for sustained, long-duration workloads
NVLink bandwidth up to 900 GB/s
NVLink Switch enables 1.8 TB/s GPU as a Service communication
Ideal for multi-node AI clusters
TDP up to 700W (SXM)
Built for high-density data centers
Supports air-cooled and liquid-cooled environments
SXM for maximum performance
PCIe for broader compatibility
The H100 is powered by NVIDIA’s Hopper architecture, which introduces major improvements for AI acceleration.
The Transformer Engine dynamically manages precision using FP8 and FP16 formats. This allows AI models to train faster while maintaining numerical stability—especially important for large language models.
MIG technology allows a single H100 GPU to be partitioned into multiple isolated instances. This enables:
Secure multi-tenant environments
Better resource utilization
Cost-effective inference deployment
Hopper integrates hardware-level optimizations for attention mechanisms, memory access, and scheduling—making it especially effective for generative AI.

Organizations using H100 GPUs typically experience:
Up to 9× faster AI training
Up to 30× faster inference
Improved scalability across clusters
Lower training costs per model
More stable production AI systems
These gains are critical for enterprises deploying AI at scale, where even small efficiency improvements can translate into significant cost savings.
| Feature | A100 | H100 |
|---|---|---|
| Architecture | Ampere | Hopper |
| Memory | HBM2 | HBM2e / HBM3 |
| FP8 Support | No | Yes |
| AI Performance | Baseline | Up to 30× Faster |
| Bandwidth | 2.04 TB/s | 3.35 TB/s |
| Power | ~400W | Up to 700W |
While the A100 gpu remains capable, the H100 GPU is designed for today’s AI workloads that require higher precision flexibility and faster interconnects.
Building an on-premise H100 infrastructure involves:
High capital expenditure
Power and cooling challenges
Limited availability
Long setup timelines
Cyfuture Cloud eliminates these barriers.
Instant H100 access
Flexible billing models
Enterprise-grade security
data center in India compliance
High-availability architecture
24/7 expert support
Cost-optimized spot instances
This allows businesses to focus on innovation rather than infrastructure management.
Chatbots and copilots
Content generation
Image and video synthesis
Predictive modeling
Customer behavior analysis
Fraud detection
Climate modeling
Drug discovery
Genomics analysis
Medical imaging
Surveillance systems
Autonomous platforms
On-premise H100 GPUs typically cost between $25,000 and $40,000+, depending on supply and configuration.
It is used for AI training, AI inference, LLM development, HPC simulations, and data analytics.
The H100 includes up to 80GB of HBM2e or HBM3 memory.
Its price reflects advanced manufacturing, high memory capacity, extreme performance, and strong global demand.
Export regulations limit availability in certain regions due to geopolitical policies.
No. The H100 is designed for professional computing, not gaming.
Yes. You can access H100 GPUs through authorized partners and cloud providers like Cyfuture Cloud.
H100, H200, and B200 are currently among the most powerful AI GPUs worldwide.
The NVIDIA H100 GPU is more than just a high-performance processor—it is the foundation of modern AI infrastructure. With Hopper architecture, FP8 Tensor Cores, massive bandwidth, and enterprise-grade reliability, it enables organizations to scale AI initiatives with confidence.
By choosing Cyfuture Cloud’s H100 GPU platform, businesses gain access to world-class AI infrastructure that is secure, scalable, and optimized for long-term growth—without the risks and costs of managing physical hardware.

Let’s talk about the future, and make it happen!

 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware on
AWS
VMware on
AWS VMware on
Azure
VMware on
Azure Service
Level Agreement
Service
Level Agreement 