 Server
Colocation
Server
Colocation
 CDN
Network
CDN
Network
 Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
 Kubernetes
Kubernetes
 API Gateway
API Gateway

In the world of artificial intelligence (AI), inference plays a central role in turning machine learning (ML) models into actionable results. The rapid adoption of AI technologies across industries has raised the need for scalable, efficient, and cost-effective methods of deploying these models. Traditional methods of deploying AI models typically rely on dedicated servers that must be managed and maintained, which can be both resource-intensive and costly.
Enter serverless inference—a revolutionary approach that has gained significant traction in the AI and cloud computing sectors. Serverless inference, as the name suggests, allows businesses to run AI models without worrying about the infrastructure or server management, thus lowering the complexity and cost. This technology is at the core of many cloud platforms today, including Cyfuture Cloud, where AI inference as a service (AIaaS) is offered to enable businesses to leverage AI capabilities seamlessly and efficiently.
According to a report by MarketsandMarkets, the global AI market size is expected to grow from $58.3 billion in 2021 to $309.6 billion by 2026, with a significant portion of this growth attributed to advancements in cloud-based AI services, including serverless architectures. This growth is driving the need for serverless inference, as companies increasingly look for ways to integrate AI seamlessly into their operations without managing the heavy lifting of infrastructure.
Serverless inference refers to the process of running AI or machine learning models for prediction (inference) without managing the underlying servers or infrastructure. With traditional cloud computing, businesses must allocate and maintain servers to handle the deployment of AI models. However, serverless computing abstracts away this need, providing a scalable and on-demand infrastructure where businesses only pay for the resources they actually use.
When using serverless inference, cloud platforms automatically handle the scaling, provisioning, and execution of AI models, allowing businesses to focus solely on the logic and performance of their AI applications. This on-demand and cost-efficient model is particularly suited for AI applications where demand is variable, or real-time processing is required.

Scalability: Serverless inference automatically scales resources up or down based on demand, ensuring that businesses can handle fluctuations in usage without overpaying for idle infrastructure.
Cost-Efficiency: With serverless computing, businesses only pay for the exact compute resources they consume, which leads to significant cost savings compared to maintaining dedicated servers.
No Infrastructure Management: Companies no longer have to worry about managing hardware, operating systems, or updates, as the cloud provider takes care of the entire infrastructure.
Real-Time Execution: Serverless inference provides low-latency results by enabling AI models to be executed instantly without the need to wait for server provisioning.
Serverless inference operates within the context of cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure, which offer fully managed services for running AI models at scale. These services typically operate through cloud functions (like AWS Lambda, Azure Functions) or containerized environments orchestrated through services like AWS Fargate.
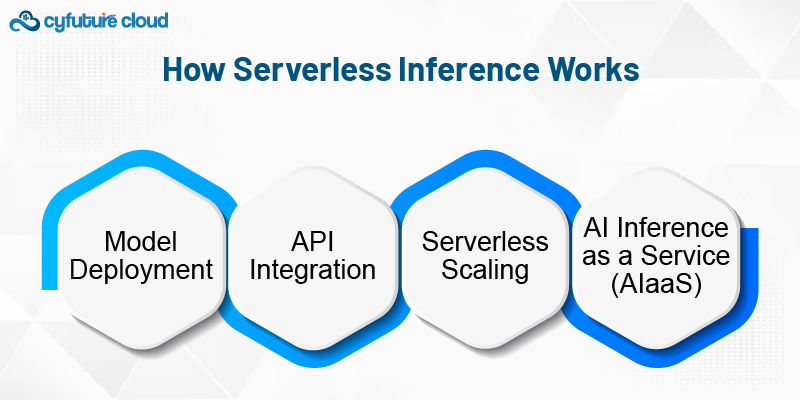
Model Deployment: A machine learning model is trained using standard ML tools (such as TensorFlow, PyTorch, or Scikit-Learn) and then deployed on a serverless platform.
API Integration: Once deployed, the model is exposed via an API that can accept incoming data, process it through the model, and return the inference results. This API can be accessed from other systems or applications.
Serverless Scaling: When an inference request is made, the serverless platform automatically provisions the resources necessary to run the model. Once the inference is complete, the resources are deallocated, ensuring that there are no wasted resources or idle time.
AI Inference as a Service (AIaaS): Companies like Cyfuture Cloud offer AI inference as a service, where customers can simply upload their models and call them as needed through an API. This eliminates the need for businesses to manage the deployment, scaling, and monitoring of AI models, allowing them to focus purely on their core operations.
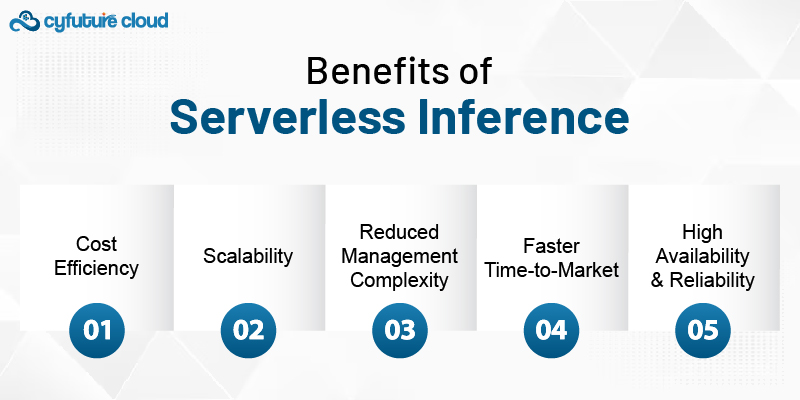
Traditional AI deployment models require the constant running of servers or dedicated resources to handle inference, even during periods of low demand. With serverless inference, however, you only pay for the time your model is active. As a result, businesses can significantly reduce their cloud costs, making it an ideal option for small to medium-sized enterprises or any business with fluctuating AI demand.
Serverless inference can scale automatically based on traffic. This scalability is particularly important for businesses with unpredictable usage patterns, where the number of inference requests can vary significantly over time. Whether you're handling thousands or millions of requests per second, the serverless infrastructure will automatically scale to meet demand, ensuring high availability and performance.
In traditional cloud environments, deploying and maintaining AI models often involves significant overhead, including managing virtual machines, load balancers, scaling, and updates. With serverless inference, the cloud provider manages all these concerns for you. This allows businesses to focus on their AI models and algorithms, without having to worry about the underlying infrastructure.
With serverless inference, businesses can deploy and iterate on AI models much faster. Since the infrastructure is managed by the cloud provider, organizations can avoid the complexities of provisioning servers and focus on quickly bringing AI capabilities to their applications.
Since cloud platforms ensure that serverless functions are always available and scale on demand, businesses benefit from high availability and reliability without needing to invest in expensive hardware or infrastructure.
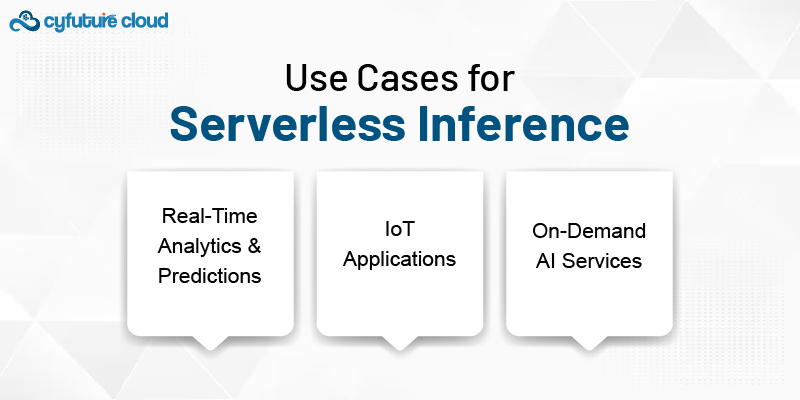
Real-Time Analytics and Predictions: For applications such as recommendation systems or fraud detection, where low-latency, real-time predictions are crucial, serverless inference offers a perfect solution. Serverless AI enables businesses to process large volumes of incoming data with minimal delay.
IoT Applications: IoT devices generate massive amounts of data that require real-time analysis. With serverless inference, these devices can send data to the cloud, where AI models can process and return predictions without the need for constant infrastructure management.
On-Demand AI Services: Businesses that offer AI-based products and services, such as image recognition or sentiment analysis, can leverage serverless inference to provide these capabilities on-demand. Whether it's for image classification or natural language processing, serverless inference makes AI accessible without the need to maintain heavy infrastructure.
Serverless inference has emerged as a game-changer for AI application deployment. By removing the complexities of infrastructure management, serverless AI enables businesses to focus on building and scaling AI solutions without the burden of managing servers. As the demand for AI continues to grow, cloud platforms like Cyfuture Cloud are leading the charge by offering AI inference as a service, making it easier for businesses of all sizes to integrate cutting-edge AI into their products.
With its ability to scale, cost-effectiveness, and simplified management, serverless inference is poised to become a standard for AI deployment in the cloud. Businesses that adopt serverless AI architectures will not only be able to save on costs but will also gain the flexibility to innovate rapidly and deliver more powerful AI applications to their users.
In a world increasingly driven by data and machine learning, serverless inference represents a critical step toward making AI accessible, efficient, and scalable for everyone.

Let’s talk about the future, and make it happen!

 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware on
AWS
VMware on
AWS VMware on
Azure
VMware on
Azure Service
Level Agreement
Service
Level Agreement 