 Server
Colocation
Server
Colocation
 CDN
Network
CDN
Network
 Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
 Kubernetes
Kubernetes
 API Gateway
API Gateway

AI is no longer the distant future. It’s the present. From healthcare diagnostics to real-time fraud detection in banking, intelligent models are running the show. In fact, according to IDC, global AI spending is expected to exceed $300 billion by 2026. But as the use of machine learning models scales, the need for efficient deployment options has become urgent.
That’s where serverless inference comes into the picture. And for businesses looking for speed, scalability, and efficiency without the overhead of traditional infrastructure, Cyfuture Cloud offers some of the most practical serverless AI deployment options in the industry today.
In this article, we’ll walk you through what serverless inferencing is, how it works, why it’s a game-changer, and exactly what options Cyfuture offers. Whether you're a developer, startup founder, or IT leader, by the end of this guide, you’ll know how to deploy and manage your ML models without touching a single server.
Before we jump into the Cyfuture Cloud ecosystem, let’s break down what we mean by serverless inference.
In simple terms, inference is the phase where a trained machine learning model is used to make predictions on new data. Traditional inference methods require running your model on dedicated servers or virtual machines, which involves provisioning, scaling, and managing the backend.
Serverless inferencing, on the other hand, eliminates the need to manage infrastructure. You upload your model, set the parameters, and let the cloud platform handle the rest. No server management. No manual scaling. You only pay for the compute you use—down to the millisecond.
In short:
You don’t need to worry about provisioning resources.
The service auto-scales based on usage.
You’re billed only for actual usage (not uptime).
Deployment becomes faster and cleaner.
Cyfuture Cloud takes this one step further by combining smart automation with enterprise-grade compute power. This lets businesses focus on building and innovating, rather than managing servers.

Let’s say you’re a fintech startup building a fraud detection engine. Your model doesn’t need to run 24/7. It only needs to respond when a transaction is made. Keeping a dedicated server running full-time? Wasteful.
That’s exactly the kind of problem serverless AI cloud hosting solves.
Here’s why it's a smart move:
Elasticity On Demand
Your model can serve 10 requests one minute and 10,000 the next—no manual intervention required.
No Hosting Headaches
With Cyfuture Cloud, you don’t worry about VMs, Kubernetes clusters, or container orchestration.
Lower TCO (Total Cost of Ownership)
No fixed infrastructure costs. You’re only billed for the compute used during inference.
Ideal for Event-Driven Applications
From chatbots and recommendation engines to voice assistants—serverless inference thrives in real-time.
With serverless inference on Cyfuture Cloud, these problems are effectively removed. Here's why it's worth considering:
Scalability without limits
You don’t need to predict traffic. Serverless environments scale automatically in response to your workload.
Cost efficiency
No pre-allocated resources. You’re charged only when your model is invoked, which makes budgeting predictable and efficient.
Faster time-to-market
Deploy models in minutes, not days. Simply upload your model and expose it via an API endpoint.
Developer-friendly
Cyfuture Cloud supports popular ML frameworks and tools, letting you focus on the model logic, not infrastructure orchestration.
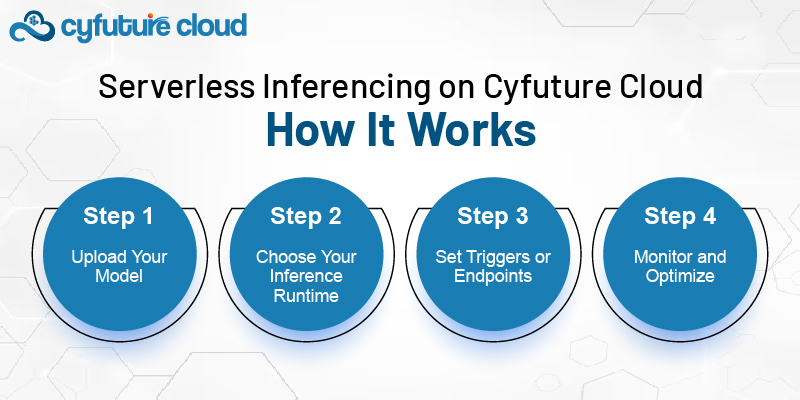
Cyfuture Cloud’s serverless inference stack is purpose-built to handle AI workloads across multiple domains—vision, text, speech, and tabular data. Here’s how it typically works:
Cyfuture Cloud supports model formats like ONNX, TensorFlow SavedModel, PyTorch TorchScript, and even custom container-based models. You simply upload the model to your workspace or storage.
Select from available runtimes depending on the framework and environment your model needs. For example:
Python (for TensorFlow/PyTorch)
Docker-based runtime (for custom apps)
Lightweight runtimes (for fast, stateless models)
Once uploaded, your model is automatically linked to a REST API endpoint. This endpoint is fully managed and scales automatically.
You can also:
Connect to external APIs
Trigger inference through event listeners (e.g., new data in a bucket)
Schedule model jobs on a timer
Cyfuture Cloud’s inbuilt analytics provide detailed reports on:
Number of invocations
Latency per request
Success/failure rates
Cost breakdown by model
Cyfuture has tailored its serverless offerings for various business use-cases. Here are some of the main options available:
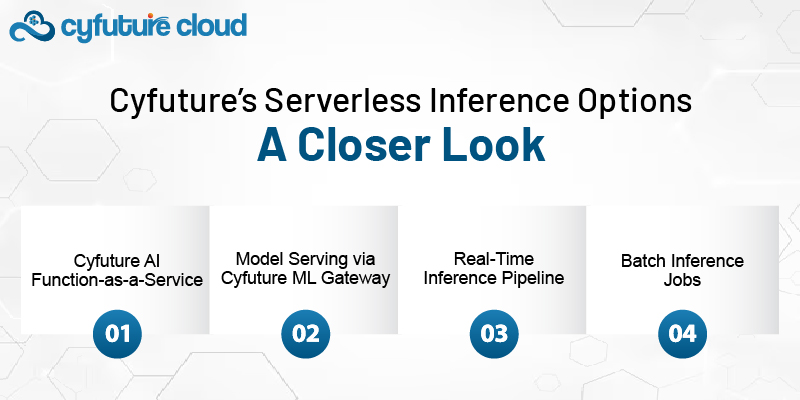
This option allows you to wrap your model into a function and deploy it without thinking about servers. It supports:
Pre-trained models
Fine-tuned models
Event-driven triggers
Usage-based billing
Example use case: An e-commerce app uses AI-FaaS to analyze customer reviews for sentiment every time a new review is posted.
This service offers API-based access to your models. It supports:
Multiple concurrent users
Auto-scaling across zones
GPU acceleration (if needed)
Version control and rollback
Example use case: A SaaS platform exposes fraud detection models to clients as a pay-per-use API.
Ideal for high-throughput applications like chatbots, recommendation systems, and voice assistants.
Features:
Sub-second latency
Multi-model orchestration
Batch or stream processing
Secure endpoints with token access
Example use case: A healthcare startup uses it to process and interpret medical images uploaded by clinics.
If your data volume is huge and time-flexible, batch inference lets you run models on datasets asynchronously. Great for:
Daily customer churn scoring
Market trend analysis
Image classification of large archives

Many cloud providers offer serverless inference, but Cyfuture Cloud brings in certain advantages that are tailored for Indian and global businesses alike:
Made for scale: Built on high-speed SSD architecture with multi-region availability.
Cost-effective pricing: Flexible options that suit both startups and enterprises.
Compliance-ready: GDPR, ISO, and Indian IT Act-compliant.
Support for Indian languages and datasets: Especially useful for local businesses building NLP models for multilingual audiences.
Moreover, Cyfuture offers dedicated customer support and model onboarding assistance—so you're never flying blind.
Let’s be honest—not every use case needs serverless inference. But it shines in scenarios where:
Workloads are event-driven or sporadic.
You want to scale without planning capacity.
Budgets are tight and cost-efficiency is key.
You want a quick proof of concept before scaling.
You’re building multi-tenant AI apps or API products.
If you're constantly trying to balance speed, scale, and simplicity, serverless is likely your best friend—and Cyfuture Cloud is your enabler.
As AI continues to evolve, so must our infrastructure. The rise of serverless inference marks a turning point in how we deploy and manage ML models—faster, lighter, and more economically.
Cyfuture Cloud delivers a rich ecosystem for serverless inferencing, allowing businesses to focus on innovation while the cloud handles the heavy lifting. Whether you’re deploying a voice recognition model or crunching large datasets, Cyfuture has serverless options ready to go.
So if you’re looking to scale your AI without scaling your infrastructure team, now’s the time to explore serverless inferencing on Cyfuture Cloud. It’s not just a trend—it’s the new normal for intelligent deployments.

Let’s talk about the future, and make it happen!

 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware on
AWS
VMware on
AWS VMware on
Azure
VMware on
Azure Service
Level Agreement
Service
Level Agreement 